Comment l'apprentissage profond révolutionne la segmentation IRM cardiaque

Que se passe-t-il si votre prochain rapport d’IRM cardiaque arrive avant que vous ayez fini votre café ?
La segmentation entièrement automatique par apprentissage profond combine un détecteur de ROI alimenté par un CNN, une architecture basée sur U-Net et un raffinement de modèle déformable pour livrer des masques de chambres parfaits en quelques secondes. Le résultat est des contours de niveau clinicien, des scores Dice supérieurs à 0,90 et des mesures d’une fraction d’éjection reproductibles.
Découvrez l’architecture, les recettes d’entraînement, les résultats de référence et les applications réelles qui rendent la segmentation IRM cardiaque rapide et fiable une réalité.

Pourquoi l’apprentissage profond révolutionne-t-il l’IRM cardiaque ?
L’IRM cardiaque nécessite traditionnellement que des experts tracent manuellement les contours des chambres, un processus lent qui peut prendre 15 à 30 minutes par scan et varie selon les lecteurs. Ces incohérences peuvent avoir un impact significatif sur des mesures clés, telles que la fraction d’éjection et le volume d’éjection, qui sont cruciales pour des décisions de traitement éclairées.
Segmentation IRM par apprentissage profond inverse ce flux de travail.
Les réseaux convolutionnels apprennent à identifier les structures cardiaques directement à partir des données d’image. Une fois formés, ils produisent des contours parfaits en quelques secondes. Cette rapidité ouvre la voie à des rapports le jour même, libérant les spécialistes pour se concentrer sur des cas complexes plutôt que sur des contourings routiniers.
Au-delà de la rapidité, la segmentation automatisée réduit la variabilité inter-observateur. Des études montrent que les modèles d’apprentissage profond atteignent des scores Dice supérieurs à 0,90 pour les ventricules gauche et droit, à égalité avec, et souvent au-dessus, de ceux des experts humains. Des mesures cohérentes renforcent la confiance des cliniciens et soutiennent un suivi fiable de la progression de la maladie.
Enfin, les réseaux modernes s’adaptent à divers protocoles d’imagerie. Grâce à l’augmentation de données et à un entraînement robuste sur des ensembles de données multi-fournisseurs, ils tolèrent les différences de marque de scanner, de force de champ et de paramètres d’acquisition. Cette généralisabilité signifie que le même modèle peut servir des hôpitaux dans le monde entier sans un réajustement laborieux.
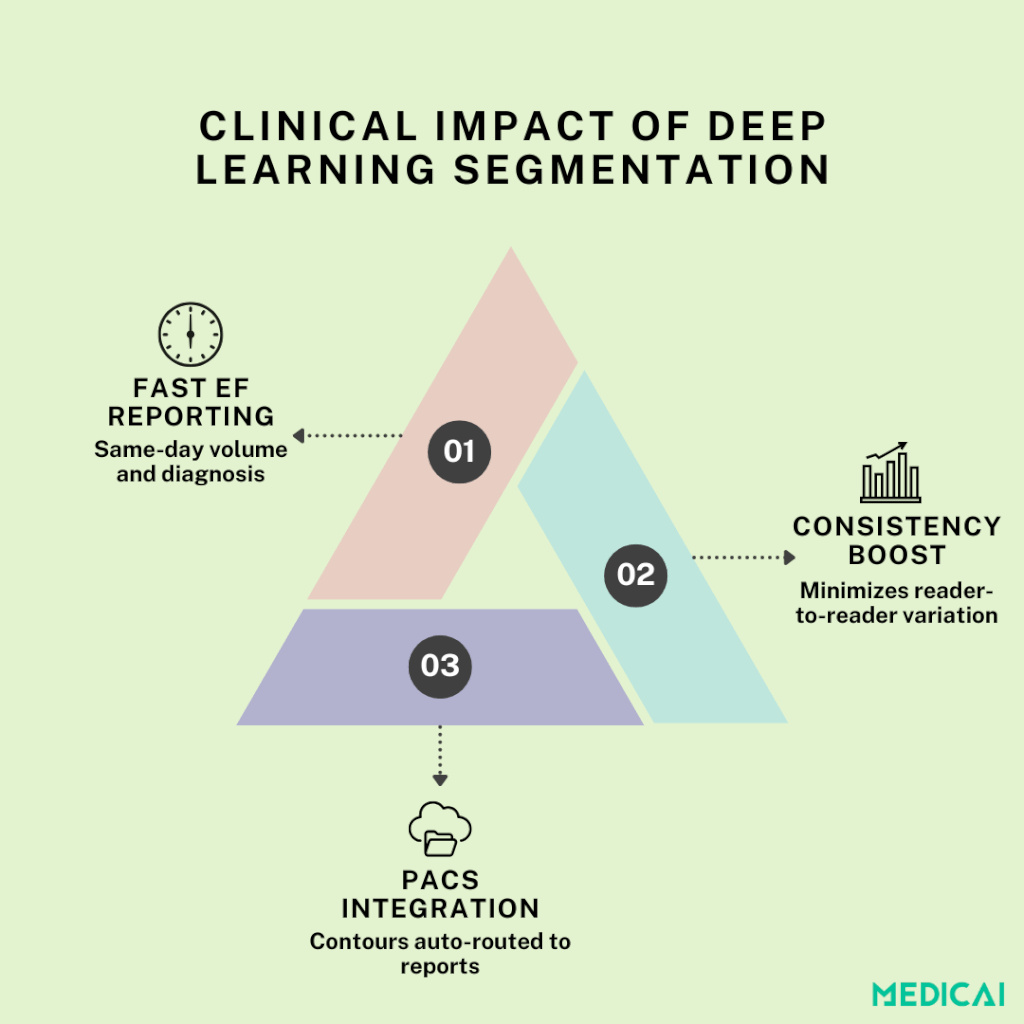
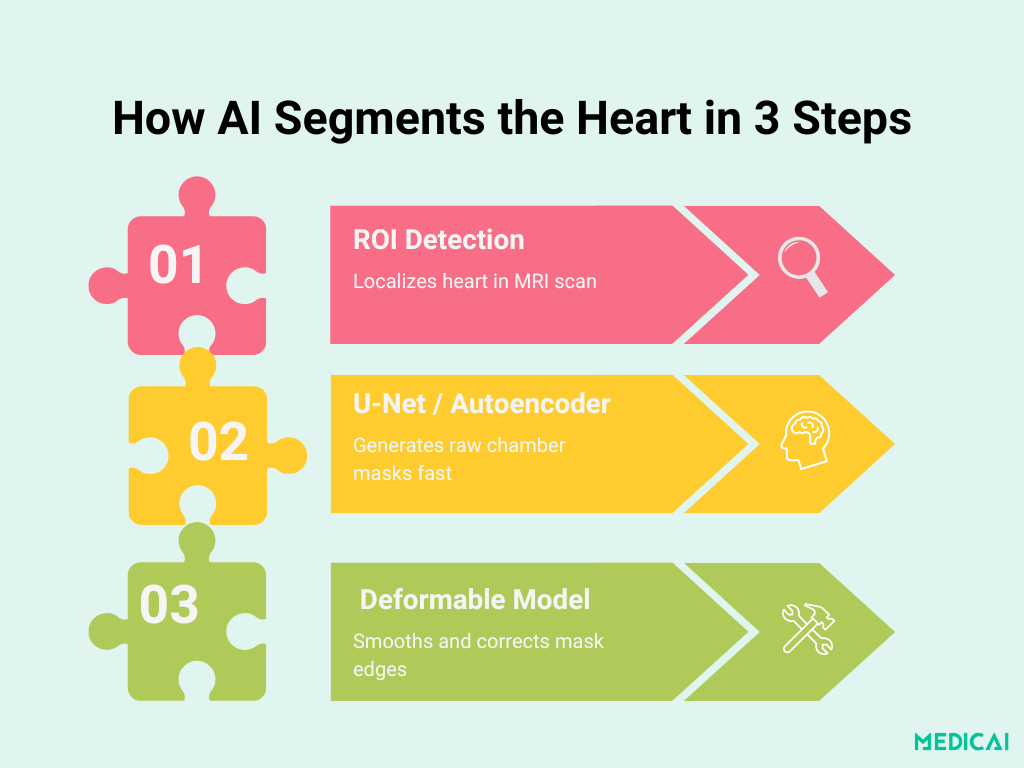
Anatomie du Pipeline : Du ROI au Contour Final
La segmentation de chambre basée sur l’apprentissage profond se déroule en trois étapes claires. Chaque étape s’appuie sur la précédente pour livrer des masques rapides, précis et anatomiquement cohérents.
Localisation du ROI cardiaque avec des CNN
La première étape utilise un réseau neuronal convolutionnel léger pour identifier la région cardiaque dans chaque coupe IRM. En s’entraînant sur des images brutes avec des boîtes englobantes annotées manuellement, le réseau apprend à éliminer l’anatomie non pertinente (telle que les poumons et la paroi thoracique) et à se concentrer uniquement sur les chambres cardiaques.
Cette cible « Région d’Intérêt » (ROI) la coupe réduit la complexité en aval et améliore à la fois la vitesse et la précision.
Base de Segmentation : U-Net & Auto-Encodeurs Empilés
Une fois le ROI extrait, un réseau de segmentation délimite les contours des chambres :
- Variantes de U-Net : De nombreuses études de premier plan utilisent une architecture U-Net 2D, caractérisée par un chemin encodeur-décodeur qui utilise des convolutions 3×3, une normalisation par lots, des activations ReLU et des connexions de saut pour préserver le contexte spatial. Les profondeurs de filtre progressent généralement de 32 à 64, puis 128 et 256, équilibrant la capture de détails et le coût computationnel.
- Auto-Encodeur Empilé (Méthode Poster) : Le pipeline du poster utilise plutôt un auto-encodeur empilé formé pour reproduire l’entrée du ROI, apprenant implicitement les formes de chambres. Son goulet d’étranglement force le réseau à distiller les caractéristiques cardiaques essentielles, produisant un masque initial par pixel qui alimente l’étape de raffinement.
Fusion de Modèle Déformable pour des Contours Parfaits
Les masques bruts de l’apprentissage profond peuvent être légèrement dentelés ou mal alignés aux bords complexes. Pour garantir la plausibilité anatomique, le contour initial s’intègre dans un modèle déformable classique :
- Initialisation : La sortie de l’auto-encodeur ou de U-Net fournit la courbe de départ.
- Minimisation d’Énergie : Les termes de forme et d’intensité guident le contour pour suivre les véritables bords de la chambre de près.
- Lissage de Sortie : Le masque final est à la fois lisse et adhère à l’anatomie précise, corrigeant les artefacts mineurs de l’apprentissage profond sans intervention manuelle.
Ce design en trois étapes combine la rapidité et la puissance d’apprentissage des CNN avec la rigueur géométrique des modèles déformables.

Entraînement du Réseau : Recettes pour une Segmentation Robuste
Construire un modèle qui se généralise à travers les patients et les scanners repose sur des fonctions de perte soigneusement choisies, une augmentation intelligente et des protocoles de validation rigoureux.
Pertes Intelligentes : Dice Rencontre Entropie Croisée
L’entropie croisée pure optimise la précision par pixel mais peut avoir des difficultés avec le déséquilibre des classes lorsque les chambres n’occupent qu’une fraction de l’image. La perte de Dice maximise le recoupement mais peut être instable au début de l’entraînement. Les combiner produit le meilleur des deux mondes :
- Entropie Croisée Pondérée : pénalise les pixels mal classifiés, maintenant le réseau ancré dans la justesse par voxel.
- Perte de Dice : maximise directement le recoupement entre la prédiction et la vérité terrain, améliorant ainsi la délimitation des bords.
- Régularisation L2 : Domptent des poids trop importants pour obtenir une convergence plus fluide.
Des études rapportent que cette perte hybride surpasse chaque composant pris séparément, augmentant les scores Dice moyens sur des ensembles de données IRM retenus de 2 à 3 points de pourcentage.
Augmentation de Données pour Battre la Variabilité des Scanners
Les protocoles IRM cardiaque varient énormément — forces de champ, épaisseurs de coupe, plans d’imagerie — donc les augmentations simulent cette diversité.
- Transformations géométriques : rotations (par exemple, multiples de 60°), mise à l’échelle, translations, flips
- Déformations Élastiques : des déformations lisses aléatoires imitent la variabilité anatomique et le mouvement respiratoire.
- Déplacements d’Intensité : des variations de contraste et de luminosité tiennent compte des différences de calibration des scanners.
Augmenter à la volée garantit que le modèle voit une variété d’exemples presque infinie, réduisant considérablement le surapprentissage et améliorant la performance inter-fournisseurs.
Stratégie d’Optimisation & de Validation
Un entraînement intense garantit que vous apprenez vraiment l’anatomie cardiaque, pas les particularités du jeu de données.
- Optimiseurs : Adam ou SGD avec un taux d’apprentissage initial d’environ 1×10⁻⁴, divisé par deux tous les 10 à 20 epochs pour affiner les poids.
- Arrêt Précoce : surveille le Dice de validation ; s’arrête lorsque l’amélioration stagne pendant 10 epochs consécutives.
- Validation Croisée : 5 splits sur des ensembles de référence (ACDC, MICCAI RV/LV) pour évaluer la stabilité et éviter les splits chanceux.
Ensemble, ces choix établissent un équilibre entre la vitesse de convergence et la généralisation, offrant des contours de niveau clinicien dans des conditions réelles.
Preuve de Performance : Métriques Qui Comptent
Évaluer la segmentation IRM la qualité repose sur trois métriques fondamentales. Chacune capture un aspect distinct de la façon dont le masque automatique correspond aux délimitations d’expert.
Coefficient de Similarité de Dice (DSC)
Le DSC mesure le recoupement volumétrique entre les masques prédits et la vérité terrain. Les valeurs vont de 0 (aucun recoupement) à 1 (recoupement parfait). Les modèles de pointe atteignent régulièrement un DSC > 0,90 pour les ventricules gauche et droit, plaçant leur précision au même niveau que celle des lecteurs experts.
Distance de Hausdorff (HD)
HD quantifie l’erreur de contour dans le pire des cas en millimètres, définie comme la plus grande distance entre un point sur un contour et le point le plus proche sur l’autre. Une HD faible (< 10 mm) indique que le masque suit avec précision les bords anatomiques fins.
Rapporter à la fois la moyenne et l’écart type de la HD aide à révéler la cohérence à travers les scans des patients.
Corrélation de Volume (R)
Les coefficients de corrélation sont utilisés pour comparer les mesures automatiques et manuelles du volume de fin de diastole (EDV), du volume de fin de systole (ESV) et de la fraction d’éjection (EF). Des valeurs de R élevées (≥ 0,99) signalent que le modèle produit des métriques quantitatives équivalentes sur le plan clinique, garantissant la confiance dans les indices fonctionnels en aval.
Impact Clinique : Plus Rapide, Cohérent, Évolutif
La segmentation de chambre alimentée par l’apprentissage profond transforme les flux de travail cliniques de trois manières clés.
Rapport de Fraction d’Éjection Automatisé
En livrant des volumes ventriculaires précis en quelques secondes, la segmentation pilotée par l’IA permet le calcul le jour même du volume de fin de diastole (EDV), du volume de fin de systole (ESV) et de la fraction d’éjection (EF). Ce retour rapide accélère le diagnostic et soutient des ajustements de traitement en temps opportun sans délais de contouring manuel.
Variabilité Inter-Observateur Minimisée
La délimitation manuelle traditionnelle souffre des différences entre lecteurs ; de petits déplacements de contour peuvent se traduire par des écarts significatifs de l’EF.
Les modèles d’apprentissage profond atteignent des scores Dice de ≥ 0,90 et des corrélations de volume de ≥ 0,99, garantissant des mesures cohérentes et renforçant la confiance des cliniciens dans le suivi des patients.
Intégration PACS/RIS Transparente
Une fois formé, le pipeline peut être directement intégré aux Systèmes de Communication et d’Archivage d’Images (PACS) fournis par des plateformes telles que Medicai ou aux Systèmes d’Information Radiologique (RIS).
Le traitement entièrement automatique ne nécessite aucune interaction de l’utilisateur, acheminant les contours finalisés et les rapports quantitatifs dans le dossier médical électronique. Ils rationalisent les charges de travail en radiologie.
Surmonter les Obstacles : Limitations & Solutions
Malgré leur promesse, l’IA dans l’IRM les pipelines de segmentation doivent résoudre trois défis persistants pour atteindre une adoption clinique généralisée.
Variabilité des Scanners
Les différences de force de champ, de séquences spécifiques au fournisseur et d’épaisseur de coupe peuvent dégrader les performances du modèle.
Les solutions incluent une augmentation des données extensive lors de l’entraînement (rotations, variations d’intensité, déformations élastiques) et un ajustement fin sur de petits lots de scans de nouveaux sites pour s’adapter aux protocoles locaux.
Pathologies Rares (par exemple, Hypertrophie)
Des conditions peu courantes comme l’hypertrophie septale asymétrique ou les malformations congénitales peuvent ne pas apparaître dans les ensembles de formation standard. Cela peut entraîner une sous-segmentation ou des distorsions de forme.
Les stratégies d’atténuation incluent des collectes de cas ciblées, une augmentation synthétique pour des anatomies extrêmes, et l’utilisation de l’estimation d’incertitude pour signaler les sorties de faible confiance à réviser.
Goulots d’Étranglement de l’Annotation des Données
Des contours manuels de haute qualité sont coûteux et intensifs en main-d’œuvre, limitant la taille des corpus d’entraînement.
Des méthodes telles que l’apprentissage semi-supervisé, l’apprentissage fédéré et l’apprentissage actif peuvent réduire le besoin de données étiquetées en utilisant des scans non marqués, en partageant des mises à jour sans transférer de données, et en se concentrant sur des cas clés.
Conclusion
L’apprentissage profond automatisé permet une segmentation rapide et précise des chambres cardiaques dans l’IRM cardiaque, fournissant des contours précis en quelques secondes. Il combine CNN pour la localisation, U-Net pour le traitement et des modèles déformables pour le raffinement afin de fournir aux cliniciens des résultats fiables.
Avec l’intégration PACS clé en main de Medicai, les mises à jour de modèle fédéré et des tableaux de bord explicables, vous pouvez déployer ce pipeline à la pointe de la technologie instantanément. Avec nous, vous pouvez fournir des soins cardiaques plus rapides et plus intelligents à chaque patient.


Articles connexes



Contactez-nous!
Découvrez comment Medicai peut vous aider à renforcer votre cabinet et à améliorer l’expérience de vos patients. Prêt à vous lancer?
Réservez une démonstration gratuite