Does AI Really Deliver Economic Value in Radiology? What the Evidence Says

Economic value from radiology AI is not guaranteed.
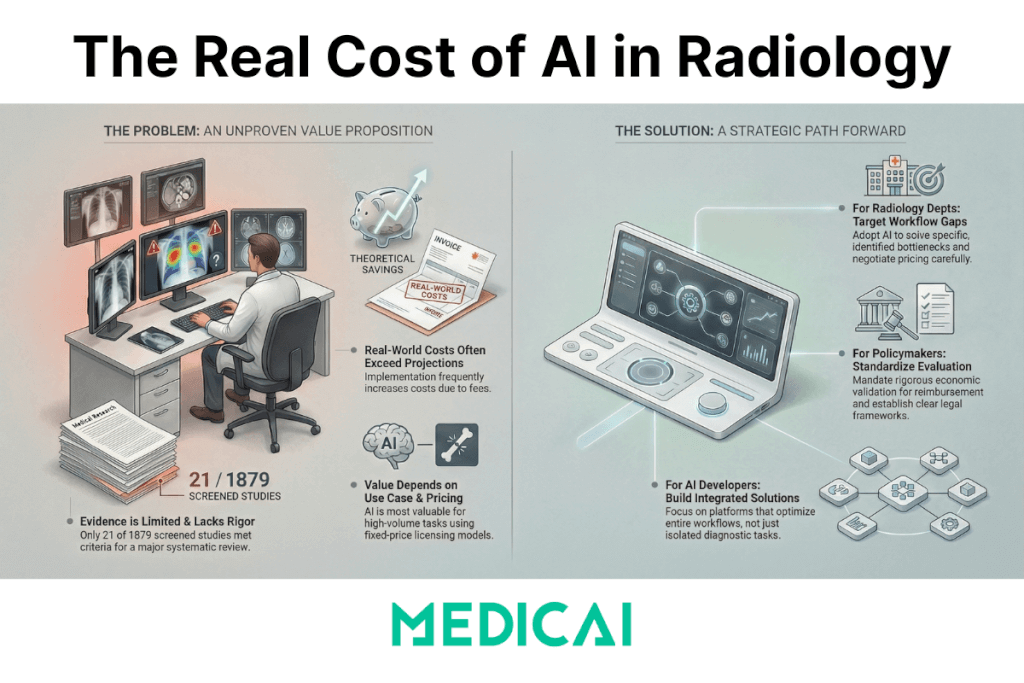
A January 2026 systematic review found that only 21 studies out of 1,879 screened records (about 1%) actually quantified economic outcomes, and the results depended on task complexity, examination volume, and the implementation model.
Radiology leaders hear “ROI” claims every week. Most of those claims start and end with model performance metrics: sensitivity, specificity, AUC. Clinical performance matters. Economic value requires a different standard: a measurable change in cost, revenue, resource use, or cost-effectiveness that survives real-world workflow constraints.
This article translates the review’s findings into operational criteria you can apply when you evaluate AI tools or AI-enabled platforms.

What the evidence actually says
The strongest recent synthesis is “Economic Value of AI in Radiology: A Systematic Review” in Radiology: Artificial Intelligence (Jan 2026).
Key facts you can reuse in decision-making discussions:
- Evidence volume is thin: 21 included studies from 1,879 screened.
- Tool categories in those 21 studies:
- 10/21 evaluated machine learning tools (9 deep learning)
- 7/21 evaluated computer-assisted diagnosis (CAD)
- 2/21 evaluated natural language processing (NLP)
- 2/21 evaluated hypothetical AI models
- Economic outcomes were mixed:
- Example upside: AI lung cancer screening reported incremental cost savings up to $242 per patient
- Example downside: CAD raised mammography screening costs up to $19 per patient, linked to specificity and pay-per-use dynamics
- The review’s core conclusion: AI’s value is context dependent, varying with task complexity, exam volume, and implementation model.
Those numbers change the tone of the conversation. They shift “AI is obviously worth it” into “AI can be worth it, when the conditions are right, and the deployment is engineered.”
How the review was done (what makes this evidence usable)
The review is valuable because it filters for studies that quantified economic outcomes, not just workflow anecdotes. The methods matter:
- Search window: January 2010 through November 2024
- Databases: PubMed, Business Source Ultimate, EconLit
- Inclusion rule: studies had to explicitly quantify economic outcomes
- Exclusion rule: studies that reported only “soft outcomes” (for example, time saved without cost quantification) were excluded
- Quality appraisal: studies were assessed using the Criteria for Health Economic Quality Evaluation (CHEC)
That filter is strict. It is the point. It explains why only 21 studies made it through.
Why AI ROI in radiology gets overestimated
AI ROI gets overstated when teams treat “better detection” as a direct proxy for “lower cost.” The cost equation has its own moving parts:
- Deployment fees (license, hosting, security, support)
- Integration cost (interfaces, validation, workflow changes)
- Downstream utilization effects (recalls, follow-up imaging, procedures)
- Operational disruption (context switching, manual reconciliation, exception handling)
- Pricing model effects (fixed cost vs pay-per-use at scale)
Economic value shows up when AI removes friction and waste across a high-volume workflow, without creating downstream demand that cancels the gains.
Where radiology AI tends to create economic value
The review points to a pattern: AI produced value in resource-intensive tasks when accuracy matched human performance and costs were fixed.
1) High-volume, resource-intensive workflows
High-volume workflows amplify small per-study improvements. Screening programs are the clearest example, because volume is predictable and the workflow is standardized.
Case example from the review: AI-assisted lung cancer screening showed incremental cost savings up to $242 per patient in one study context.
The mechanism is not “AI is smart.” The mechanism is operational: fewer avoidable steps, fewer expensive downstream actions, and a workflow that runs the same way thousands of times.
2) Fixed-cost deployment that lets you scale use
A fixed-cost model changes the math. It allows an imaging service to apply AI consistently as volume rises without paying more per exam. The review explicitly links value to cases where “costs were fixed.”
A pay-per-use model can work in low-volume settings. In high-volume settings, it can turn “clinical benefit” into “margin leakage.”
3) Settings where speed is constrained by staffing
The review notes that in “fast tasks such as radiograph evaluations,” AI showed value in settings with radiologist shortages.
That is an important nuance: if the baseline task is already fast, economic value requires a constraint somewhere else (coverage, backlog, after-hours staffing, interruption load). AI becomes valuable when it reduces the cost of being constrained.
4) Protocol optimization and follow-up compliance
The review reports that AI reduced costs through protocol optimization and increased revenue through improved follow-up compliance.
This category is easy to miss because it is not “AI reads images.” It is “AI improves the economics around imaging,” which is often where the hidden dollars sit.
Where radiology AI increases costs
The review gives a concrete warning: AI increased costs when specificity was lower than humans’ or when the pricing model was pay-per-use.
1) Low specificity that drives false positives and downstream care
False positives do not just add radiologist minutes. They can trigger additional imaging, procedures, administrative work, and patient anxiety. Even a modest specificity drop can multiply into real cost in screening workflows.
2) Pay-per-use pricing that penalizes scale
The downside example in the review is direct: CAD systems raised mammography screening costs up to $19 per patient.
That result is tied to how specificity and pay-per-use dynamics behave in real screening operations: each incremental “maybe” creates a chain of work, and each exam creates another fee.
3) Standalone tools that sit outside the core workflow
Standalone AI introduces workflow fragmentation: separate logins, separate queues, separate exceptions. The tool can be accurate and still be economically negative if it adds friction that the team must absorb.
Conditions linked to value: what to measure before you buy
Use this table as a procurement checklist. It turns vendor claims into measurable conditions.
| Condition | Why it matters economically | What to measure in your environment |
|---|---|---|
| High exam volume in a standardized workflow | Small per-exam gains compound only when volume is predictable | Exams/month by modality and use case, baseline turnaround time (TAT), backlog hours |
| Specificity comparable to human performance | Low specificity drives recalls, follow-ups, and downstream cost | False-positive rate vs baseline, downstream imaging rate, recall rate (screening) |
| Fixed-cost deployment at scale | Pay-per-use can erase gains in high-volume settings | Effective cost per exam at your projected volume, marginal cost when volume rises |
| Workflow-embedded use (PACS/reporting) | Context switching and exception handling create hidden labor cost | Clicks/steps per case, time in non-clinical tasks, number of “manual reconciliation” events |
| Clear operational constraint (staffing, coverage, bottleneck) | AI produces value when it relieves a real constraint | After-hours coverage cost, interruption rate, queue aging, overtime and locums spend |
| Measurement plan with economic endpoints | “Time saved” without cost linkage does not prove value | Cost per case, cost per detected cancer (screening), ICER/QALY where relevant, budget impact |
The question to settle for every AI deployment is simple: which row is your “yes,” and what metric will prove it six months after go-live?
What imaging leaders should ask vendors, in the language the evidence supports
Replace “How accurate is the model?” with questions that match the review’s economic patterns:
- What is the tool’s specificity in a population that matches our case mix, and what downstream actions does a false positive trigger in our workflow?
- What is the pricing model at our expected volume, and what is the effective cost per exam at month 1, month 6, month 12?
- Where does the tool live in daily work: inside PACS/reporting, or in a parallel workflow?
- What operational constraint does it remove: backlog, coverage, protocol variability, follow-up leakage, administrative burden?
- What economic endpoint does the vendor agree to measure with us: budget impact, cost per case, TAT-linked staffing cost, follow-up completion rate?
That framing stays aligned with what the evidence can support today: context, volume, implementation model.
Where Medicai fits, framed the evidence-first way
Medicai should be positioned as “designed for the conditions linked to value,” not as “proof that AI always pays off.”
The review points to value when AI is deployed in high-volume, resource-intensive workflows, with fixed-cost economics and workflow integration that avoids fragmentation.
A cloud PACS and workflow layer can reduce integration overhead, reduce context switching, and make measurement easier by centralizing the imaging workflow. In that frame, Medicai is not “the evidence.”
Medicai is an infrastructure that can make it easier to meet the conditions associated with value, as the evidence suggests.
That language reads like implementation reality, not vendor logic.
Radiology AI can deliver economic value. The current evidence base is small, and the outcomes depend on task complexity, exam volume, and deployment model.
If you want AI to pay off, engineer for the conditions that the evidence keeps pointing back to: high-volume workflows, strong specificity, fixed-cost scaling, and workflow-embedded deployment with a measurement plan tied to real economic endpoints.


Related Articles


Lets get in touch!
Learn more about how Medicai can help you strengthen your practice and improve your patients’ experience. Ready to start your Journey?
Book A Free Demo